Dans un billet récentécrit à l'occasion des dix ans de XML, Jean-Michel Salaün regrettait que les pistes esquissés dans le second texte de l'initiative Roger T. Pédauque intitulé « Le texte en jeu. Permanences et transformations du document » n'aient pas été suivies. Et, pour cause me semble-t-il, si ce deuxième article, comme les deux autres d'ailleurs, apporte incontestablement des pistes de réflexion et certaines idées intéressantes, il comprend des contre-sens et des erreurs si manifestes qu'il n'est possible de s'en servir comme base de travail qu'après une critique attentive, sans compter sur le style que Jean-Michel Salaün lui-même dans le billet cité plus haut qualifie « d'un peu abscons » et que je qualifierais plus volontiers de charabia jargonnant.
A l'heure où le Web sémantique pointe avec plus de prégnance le bout de son nez, il n'est pas inutile de revenir sur ce texte, comme sur les deux autres, pour construire une nouvelle réflexion. C'était d'ailleurs leur but : susciter le débat et la réflexion, sans présager des évolutions futures et selon l'état de l'art du moment. Or, il semble bien qu'une nouvelle étape est sur le point d'être franchie, si ce n'est pas déjà le cas. A titre personnel, si, à l'époque de rédaction du texte, je n'étais pas en mesure de m'immiscer dans le débat, j'espère, aujourd'hui, pouvoir apporter ma pierre à l'édifice.
Avant d'entrer dans le vif du sujet, je voudrais rappeler, pour mémoire, que cette initiative avait été lancée par le réseau thématiques pluridisciplinaires dédié au document, le RTP-DOC d'où le pseudonyme Roger T. Pédauque pour signer les textes collectifs, placé sous le patronage de feu le département STIC du CNRS. L'objectif était de réfléchir selon une approche pluridisciplinaire à la notion de document dans le contexte des changements induits par le numérique.
<!--break-->1- Retour sur la notion de texte et son analyse
Si je souscris totalement à la méthodologie initiale annoncée, à savoir repartir de la notion de texte pour redéfinir le concept de document, il est erroné d'affirmer que cette notion n'a pas été étudiée par les chercheurs, en particulier les linguistes, lorsque les premières DTD ont été créés pour SGML au début des années 1990 en vue d'encoder des textes .
Il existe des références incontournables dans la littérature anglo-saxonne, à commencer par l'article fondamental de Steven DeRose, David Durand, Elli Mylonas et Allen Renear, « What is text, really ? » paru en 1990 dans la revue Journal of Computing in Higher education. Je vous engage à relire cet article, écrit au moment où l'initiative de la TEI n'en est qu'à ses balbutiements, tant il reste encore d'actualité1. Les auteurs démontrent la pertinence du modèle de construction hiérarchique de la structure logique d'un texte qu'ils nomment le modèle OHCO (Ordered hierarchy of content object) et qui constitue la base des langages à balise, de SGML et, donc de XML. A travers différents exemples, ils montrent l'apport de ce modèle pour l'exploitation informatique du texte.
Évidemment, le modèle du codex imprimé est encore très présent dans les idées exposées, mais cet article dont il faut se souvenir de la date de rédaction constitue une base indéfectible et citée encore régulièrement par les spécialistes de l'encodage. Les auteurs ont précisé certaines idées dans un second article : « Refining our Notion of What Text Really Is: The Problem of Overlapping Hierarchies », revenant sur le problème bien connu de l'overlapping, problématique absente, malheureusement, de l'article de Roger.
De même, il n'est pas une présentation, formation, tutoriel sur la TEI, sans retour initial sur la notion de textes. Il suffit pour s'en convaincre de parcourir les documents mis à disposition sur le site du consortium. M'inspirant modestement de ces documents pour ma présentation de la TEI à l'ADBS, il y a quelques semaines, j'avais proposé cette définition à la notion de texte :
« Un texte est la représentation sur un support d’une construction logique de phrases formant une unité. »
Elle n'est évidemment ni complète, ni parfaite, à commencer par l'utilisation de la notion de phrase que je remplacerais par « portions d'information ». En effet, et c'est une seconde erreur de l'article de Roger, les DTD créées pour encoder le texte ne reposent pas sur le concept de phrases, mais sur un concept plus générique de divisions ou blocs d'information, la fameuse balise <div> que l'on retrouve aussi bien dans TEI, docbook que HTML et, à un niveau de granularité plus restreint, au concept de chaînes de caractères référencées (inline element), qui prend la forme de la balise <rs> et dérivés (persName, geoName, hi, emph...) dans la TEI ou <span> en HTML. L'erreur des auteurs de l'article repose, mais peut-être que je me trompe, sur l'idée que ces différentes DTD ont été construites par des linguistes. Si on ne peut nier leur apport, il ne faut pas oublier que la TEI a été créée par des chercheurs issus de toutes les disciplines des sciences humaines, que Docbook a été créé par Norm Walsh qui, aux dernières nouvelles, n'est pas linguiste, et que HTML a été créé par Tim Berners-Lee, qu'on ne présente plus.
Ainsi, si le postulat de départ est bon, l'état de l'art ne semble pas complet2 ce qui entraîne des fausses affirmations et, aussi, peut-être, une mauvaise interprétation du but et du rôle de XML dans l'exploitation informatique des textes ce que viennent, d'ailleurs, confirmer les deux problèmes suivants.
2- La fausse croyance de la prévalence du fond sur la forme
Voilà, un argument maintes fois entendu, l'utilisation de XML étant basé sur la séparation entre la structure logique du texte (désigné par les termes « fond » et « contenu » dans l'article) et sa structure physique (sa mise en forme), l'apport de la forme (mise en page, graphisme, design) à l'appréhension et à la compréhension du texte serait nié par les mécanismes d'encodage. Il existerait une prévalence implicite du fond sur la forme. Il me semble que cet argument est le signe d'une incompréhension des raisons qui ont poussé à cette séparation et d'une méconnaissance du fonctionnement concret de XML.
Repartons, si vous le voulez bien, des buts qui ont vu la mise en place de la TEI, qui constitue la première DTD pour encoder les textes et une source d'inspiration pour les suivantes. Le but initial était de partager une syntaxe et des règles communes de balisage en vue de l'échange des corpus informatisés. Cette idée est d'ailleurs toujours présente dans la TEI, puisque le guidelines a pour titre, Guidelines for Electronic text encoding and Interchange. Dans ce contexte, l'encodage de la structuration logique du texte assurait l'échange du texte dans une version facilement exploitable par des logiciels et des applications. La séparation entre structure logique et structure physique ne relève donc pas d'une quelconque posture épistémologique, mais constitue plutôt un moyen d'assurer l'échange et l'exploitation du texte encodé dans des contextes différents3.
Pour autant, structure logique ne signifie pas forcément que les caractéristiques physiques d'un texte ne sont pas encodées. Cela dépend tout simplement du but poursuivi et des besoins de traitement du texte. C'est d'ailleurs la raison pour laquelle j'ai conservé la notion de « support » dans ma définition du texte. La TEI offre précisément les moyens d'encoder toutes les caractéristiques physiques du texte traité, dans la mesure où ils font partie intégrante de son appréhension et méritent, à ce titre, un traitement particulier. Citons, par exemple, le changement de ligne (<lb/>), le changement de page (<pb/>), le changement de mains dans un document manuscrit (<handSchift/>), ou encore les abréviations (<abbr>) pour rester dans le registre de la paléographie.
Par ailleurs, la TEI offre avec l'attribut rend disponible pour tous les éléments la possibilité d'indiquer le rendu/la mise en forme de la portion encodée. L'attribut style joue exactement le même rôle pour HTML. De plus, toujours en HTML, toutes les pages possèdent un lien vers une feuille de style qui exprime la mise en forme de la page grâce au langage CSS, format tout aussi pérenne, ouvert et libre que XML. Ce mécanisme de lien est très clairement exprimé dans les recommandations de HTML. D'ailleurs, la montée en puissance, ces dernières années, du couple HTML-CSS est une preuve que la séparation n'est pas vécue comme un abandon de la forme, mais plutôt comme un moyen de rationaliser le développement de sites Web, d'en assurer un suivi, une maintenance et une évolution simplifiés, tout en économisant de la bande passante.
Enfin, un dernier exemple démontre l'irrecevabilité de cet argument : la mise au point récente et l'utilisation de schémas XML pour décrire les documents issus d'un traitement de texte. Dans ce cas, le fichier XML comprend des informations de mise en forme physique du texte ce qui démontre bien que cette séparation n'est pas à faire sur le contenu lui-même, mais sur la structure logique. Or, dans ce cas, la mise en forme participe de la structure logique du texte, c'est pourquoi la plupart des informations de mise en forme sont présents directement dans le fichier XML.
3- XML et la grammatisation du document
Cette connaissance approximative du rôle et du fonctionnement de XML apparaît de manière encore plus explicite dans la thèse qui sous-tend l'ensemble de l'article, à savoir les rapports entre XML et l'évolution de la grammatisation du document.
Les auteurs appliquent, à l'évolution des langages documentaires utilisant XML, le concept de « grammatisation » forgé par Sylvain Auroux, à la suite de Jacques Derrida, et qui désigne la matérialisation de « la substance d'une expression en éléments matériels discrets et manipulables ». Ce faisant, ils distinguent trois postures dans l'utilisation de la syntaxe XML marquant un contrôle de plus en plus accru du contenu du texte :
- « DTD », dont le but est d'annoter et de manipuler des documents ;
- « Schémas », dont le but est d'échanger des données entre applications ;
- « RDF/S, Ontologies/OWL » dont le but est d'effectuer des inférences formelles sur le contenu.
Or, cette analyse pose plusieurs problèmes. En premier lieu, elle traduit une confusion de taille entre la syntaxe XML et le modèle d'encodage de l'information sous-tendu par XML, à savoir un arbre. Si les deux premières postures utilisent à fois XML en tant que syntaxe et en tant que modèle, la troisième posture a pour base le modèle de graphes, sous-tendu par l'utilisation de RDF, et peut se traduire par une syntaxe XML, mais aussi d'autres syntaxes : Turtle, N-triples ou N3.
L'information encodée grâce aux DTD et aux Schémas forme un arbre dont les nœuds sont constituées par les différents éléments ou balises utilisés. Dans le cas de RDF, l'information encodée forme un graphe, selon le schéma « sujet-prédicat-objet » et constitue un modèle plus générique d'encodage de l'information, l'arbre étant un type particulier de graphes.
Cette distinction entre modèle et syntaxe est d'autant plus importante que les deux premières postures n'ont pas le même rôle que la troisième. Les DTD et les schémas définissent un cadre ou une grammaire pour valider la structure de l'information encodée en vue de son échange et/ou d'une transformation, qui, au passage, ne pose aucun problème grâce à l'utilisation de XSL4. RDF schéma et OWL permettent de définir les relations entre différents types de ressources (document, page Web, objet, personne, concept...) pour échanger des données hétérogènes et y appliquer des inférences. Par exemple, une ontologie définie selon RDFS ou OWL permet de définir qu'une ressource de type « Personne » entretient une relation de nature « connaît » avec une autre ressource de type « Personne ». Ils ne servent en aucun cas à valider un document RDF. Ils offrent « simplement » un vocabulaire commun pour exprimer des prédicats sur des types de ressources.
De plus, la structuration d'information en XML selon un cadre défini dans une DTD ou un schéma dépend d'un contexte précis et se pense sur l'ensemble de l'information encodée. Ainsi, une même information peut être encodée de manière complètement différente tout en restant valide selon un schéma et sans que la nature du message soit différente. La structuration d'information en RDF se conçoit, quant à elle, au plus proche de la donnée elle-même dans le contenu même du message véhiculé par l'information.
De ce point de vue, le modèle exprime une idée tout à fait juste, à savoir que ces trois postures constituent une évolution dans l'exploitation de différents niveaux de granularité de l'information, pour en arriver à l'exploitation par une machine du message véhiculé par l'information. Pour autant, si les « Schémas » constituent bien une évolution des « DTD », offrant la possibilité de contrôler les types de données comme une date, une chaîne de caractères, un booléen.., la troisième posture relève d'un paradigme différent et ne peut être assimilé à une évolution, mais plutôt à un complément.
D'ailleurs, les deux aspects ont évolué de façon concomitante ces dernières années. La communauté XML a mis au point des technologies telles que Relax NG ou schematron pour mieux contrôler et valider la structure des données, offrant les outils pour vérifier ce que les auteurs nomment la « validité sémantique », tandis que la communauté RDF a amélioré les moyens de définir une ontologie avec OWL mais aussi d'autres systèmes d'organisation des connaissances, comme les thésaurus avec SKOS. De même, deux langages de requêtes spécifiques ont été développées, Xquery pour XML et SPARQL pour RDF ce qui démontre bien que les deux modèles sont différents.
Enfin, un aspect essentiel a été occulté dans cette analyse. A aucun moment, les auteurs n'introduisent le rôle joué par le protocole HTTP et le concept des URI dans cette évolution. Or, l'échange de données entre les applications n'est possible que dans la mesure où nous disposons à la fois avec XML d'une syntaxe indépendante des plates-formes et des logiciels, mais aussi d'une couche de transport, un protocole de communication commun, HTTP et dans ce réseau, un moyen normalisé d'identifier et de localiser une ressource grâce aux URI. Ainsi, XML schéma représente bien une évolution naturelle dans les outils de validation et de contrôle de l'information encodée, mais il ne saurait être dissocié de HTTP, s'il est conçu dans le cadre des échanges de données entre applications. Or, si les grands éditeurs (IBM, Sun, Microsoft, Oracle, SAP et consorts) se sont rués sur XML et en ont fait la base des architectures SOA, c'est précisément, parce que le couple HTTP+XML constituait la réponse à la problématique des middlewares et de l'EAI, très en vogue à l'époque et largement remis en cause aujourd'hui.
4- Le Web sémantique ne se limite pas aux ontologies !
La confusion évoquée précédemment provient certainement d'une mauvaise interprétation des buts poursuivis par le Web sémantique et, dans ce cadre, du rôle précis de RDF et des ontologies. De ce point de vue, cet article constitue un bon exemple des méprises dont je parlais dans un précédent billet.
Ainsi, pour les auteurs, le Web sémantique vise à « construire un métalangage, fondé sur les ontologies, représentant de façon formelle le contenu des documents qui pourra donc servir de base à des modélisations informatiques ». Or, les ontologies ne constituent pas la base du Web sémantique, mais elles y participent, constituant une des briques. C'est RDF, dont il est fait malheureusement trop peu allusion dans l'article, qui constitue la base des technologies du web sémantique. En limitant le Web sémantique aux ontologies, les auteurs ont naturellement porté le débat sur les problématiques déjà connus dans l'intelligence artificielle, à savoir, pour faire court, la dangerosité de modéliser l'ensemble des connaissances du monde selon une ontologie imposée et unique ce qui réduit inévitablement le sens porté par un texte à une interprétation. De ce point de vue, la partie intitulée « Questionner le Web sémantique » est un conglomérat de tous les fantasmes véhiculés par cette idée d'ontologie universelle.
Or, comme le rappelle James Hendler dans cette réponse à Clay Shirky, au contraire de systèmes traditionnelles de représentation de la connaissance (les bases de connaissances auxquels fait allusion l'article) centralisés et imposant de partager la même définition des concepts communs, le Web sémantique est plus flexible et n'impose pas l'utilisation d'une seule ontologie, les mécanismes étant suffisamment puissants pour introduire des inférences entre deux données qui n'utilisent pas la même ontologie. Cette puissance est offerte par le modèle de base qui sous-tend tout l'édifice du Web sémantique, à savoir RDF. Ainsi, contrairement à ce qu'affirment l'article et les tenants du concept de Web socio-sémantique, le Web sémantique n'est pas anti-social et ne dépendrait pas d'une communauté ou d'un contexte social donné et imposé.
Même si les technologies du Web sémantique offrent le moyen de représenter « de manière formelle des contenus [nda : est-ce à assimiler à la notion de texte ?] via les ontologies » en vue d'une exploitation par une machine, le but initial du Web sémantique est plutôt d'échanger à une très large échelle des données de nature hétérogènes, ce que ne permet pas XML qui impose l'utilisation de schémas identiques ou une transformation préalable, et, éventuellement, grâce aux systèmes des ontologies, d'y appliquer des mécanismes simples d'inférence. Ainsi, le Web sémantique ne s'intéresse pas directement au texte en lui-même, mais aux données qui le décrivent ou le caractérisent, ce qu'on appelle communément les métadonnées, ou à des données précises à l'intérieur du texte comme le permet RDFa.
5- Évolution du Web sémantique depuis l'écriture de l'article
L'article constitue un bon point de repère pour évaluer l'évolution du Web sémantique et son appropriation. Les différentes briques et technologies du Web sémantique sont habituellement représentées sous la forme d'un cake. Or, au gré des recherches, ce cake évolue et la dernière version est largement différente de la version proposée par l'article.
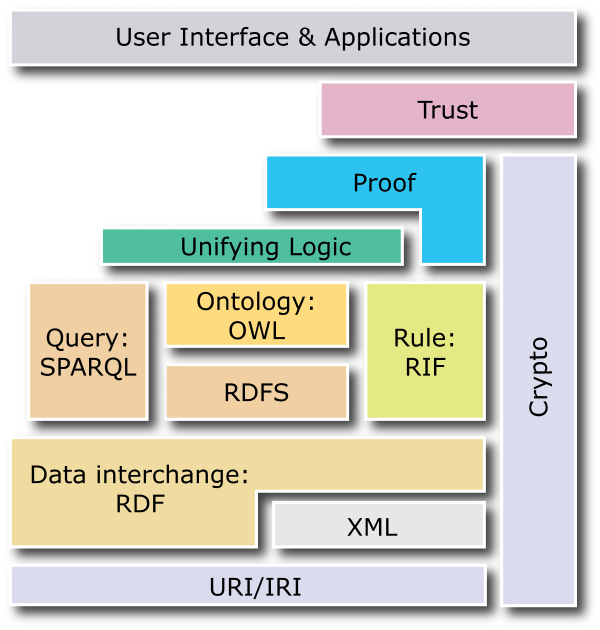
Dans cette nouvelle version, à la base, nous trouvons toujours les URI qui permettent d'identifier les ressources (sujet ou, éventuellement, objet d'un triple) et les prédicats. RDF est le modèle de base pour l'échange des données et peut éventuellement s'appuyer sur XML, dans le cas de l'utilisation de la syntaxe RDF/XML. Au-dessus, on trouve SPARQL pour effectuer des requêtes, RDFS et OWL pour définir des vocabulaires RDF, assimilables à des ontologies et RIF, un langage de définition de règles. XML schema et les namespaces ont complètement disparus du cake, englobés dans la brique XML.
De même, si, à terme, les technologies du Web sémantique devrait améliorer la recherche d'information par une meilleure caractérisation des données et des relations qu'elles entretiennent entre elles, nous savons aujourd'hui que cela n'est pas son but initial, mais plutôt une conséquence. Ainsi, à une vision top-down qui a longtemps été l'axe privilégié par les recherches sur le Web sémantique, il se substitue peu à peu, entre autres par l'écosystème initié par le Web 2.0, une approche bottom-up dans lequel ce sont les annotations portés par l'utilisateur ou les données structurés qu'ils génèrent qui sont exploitées par les technologies du Web sémantique. De ce point de vue, Dbpedia est un exemple parfait. Partant du contenu mis à disposition sur wikipedia, le projet Dbpedia vise à mettre à disposition cette masse d'informations en RDF pour une meilleure exploitation par les machines de ce gisement de données.
6- Retour sur l'exemple donnée en annexe de l'article
En annexe du document, un exemple illustre les trois postures abordés dans l'article. Malheureusement, il comprend un certain nombre d'erreurs. Ainsi, le manque de maîtrise des technologies dont il est fait preuve pourrait expliquer en partie les contre-sens de l'article.
L'exemple utilisant une DTD ne pose pas de problèmes particuliers, si ce n'est qu'il aurait mérité un balisage plus fin. Si, à première vue, le schéma semble bien défini dans le second exemple, sa déclaration est complètement fausse. Dans le cas d'un schéma, il ne faut pas utiliser de doctype, le schéma étant déclaré dans l'élément racine du fichier XML. De plus, il est obligatoire de déclarer l'espace de nom par défaut correspondant au schéma XML ce qui nous donne :
<?xml version="1.0" encoding="UTF-8"?>
<CRH
xmlns="http://www.rogerpedauque.fr/casclinique/ns/"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.rogerpedauque.fr/casclinique/ns/ http://www.rogerpedauque.fr/casclinique/ns/casclinique.xsd">
[...]
</CRH>
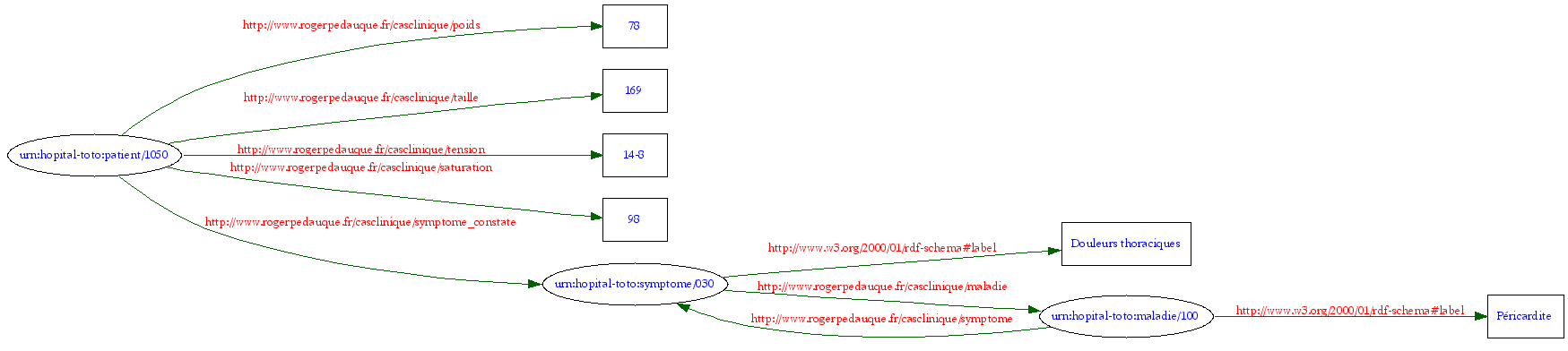
L'exemple de RDF est complètement faux et démontre une incompréhension totale de son fonctionnement : les espaces de noms ne sont pas déclarés, il met en lumière la confusion entre le modèle XML et le modèle RDF. Voici approximativement ce qu'il pourrait obtenir :
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:med="http://www.rogerpedauque.fr/casclinique/">
<rdf:Description rdf:about="urn:hopital-toto:patient/1050">
<med:poids>78</med:poids>
<med:taille>169</med:taille>
<med:tension>14-8</med:tension>
<med:saturation>98</med:saturation>
<med:symptome_constate rdf:resource="urn:hopital-toto:symptome/030"/>
</rdf:Description>
<rdf:Description rdf:about="urn:hopital-toto:symptomes/030">
<rdfs:label>Douleurs thoraciques</rdfs:label>
<med:maladie rdf:resource="urn:hopital-toto:maladie/100"/>
</rdf:Description>
<rdf:Description rdf:about="urn:hopital-toto:maladie/100">
<rdfs:label>Péricardite</rdfs:label>
<med:symptome rdf:resource="urn:hopital-toto:symptome/030"/>
</rdf:Description>
</rdf:RDF>
En guise de conclusion
Outre les contre-sens relevés, il me semble que l'analyse et la réflexion n'ont pas été menées à son terme. C'est finalement le plus frustrant dans cet article, ses conclusions ne sont pas à la hauteur de ses ambitions. Ainsi, il n'aboutit à aucune définition concrète et simple de la notion de texte au point même que l'interrogation initiale disparaît peu à peu et, lorsqu'il aborde les pistes les plus intéressantes, il ne la poursuit pas. Or, une phrase et une idée me paraît essentiel dans cet article : « On peut se demander dans ce modèle [nda : le Web sémantique] si la notion de document a encore un sens ». Voilà, précisément, la question essentielle à se poser !
Quelques notes en passant
1Les auteurs de l'article étaient d'ailleurs pour la plupart impliqués dans l'élaboration de la TEI.
2Pour connaître certains des auteurs de l'article de Roger, je sais pertinemment qu'il connaisse parfaitement les deux articles d'Allen Renear et alii.
3Le principe est le même pour LaTeX et je ne crois pas avoir entendu cet argument le concernant, tant il tomberait très rapidement à l'eau vu le profil des développeurs originaux de ce logiciel.
4p. 22, les auteurs affirment : « en l'état actuel de la technologie, peu de langages transformationnels sont capables de garantir l'invariance de niveau 1 (le résultat ne sera pas nécessairement bien formé) et aucun ne préserve le niveau 2 [nda : la validité de l'encodage de l'information selon un schéma] », alors que XSL qui date de 1999 garantit précisément ces deux niveaux de validité...